تحقیقات جدید از شرکت دیپ مایند بریتانیا به عنوان یکی از شرکت های زیرشاخه گوگل، نشان می دهد که یک AI با شبکه های عصبی عمیق دارای ظرفیت قابل توجهی برای درک صحنه ها می باشد، آن می تواند عکس ها را در یک فرم جمع و جور برای خود نشان دهد و سپس تصور کند که همان صحنه در فضای سه بعدی چگونه خواهد بود در حالی که شبکه عصبی اصلا آن صحنه را از قبل ندیده است.
انسانها در این مورد خوب هستند.
اگر یک تصویر از یک میز با تنها سه پای در جلو دیده شود، بیشتر مردم به طور مستقیم متوجه می شوند که میز احتمالا دارای یک پایه چهارم در طرف مقابل نیز است و آن پایه پشت میز احتمالا همان رنگی می باشد که جاهای دیگر آن میز هستند.
همچنین با تمرین، می توانیم یاد بگیریم صحنه را از زاویه دیگر، با توجه به حساب کردن چشم انداز کلی، سایه و سایر جلوه های دیداری دیگر، برای خود تجسم کنیم.
تیم DeepMind به رهبری علی اسلامی و Danilo Rezende نرم افزاری را بر اساس شبکه های عصبی عمیق با همان توانایی های دید و تجسم انسان ها، حداقل برای صحنه های هندسی ساده ساخته است.
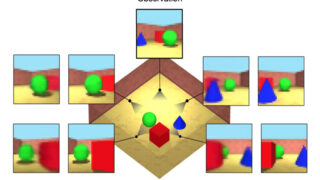
شما می توانید به نرم افزار تعداد انگشت شماری از عکس های فوری یک صحنه واقعی و یا مجازی را بدهید، سپس نرم افزار به عنوان یک شبکه پرس و جو نسبی و مستقل (GQN) و با استفاده از یک شبکه عصبی، به خود یک نمایش الگوریتم مانند از صحنه را نشان می دهد.
و در نهایت برنامه از این تصویر بازبینی شده استفاده می کند تا تصاویر را از دیدگاه های جدیدی پیش بینی و تجسم کند که شبکه عصبی قبلا آن ها را ندیده است.
محققان هر گونه اطلاعات قبلی و یا کدی را برای نوع محیط هایی که برنامه می تواند در GQN رندر کند و ارائه دهد، طراحی نکرده اند.
انسانها می توانند با تمرین دادن این AI و هربار اضافه کردن عکس ها برای نتیجه گرفتن، بعد از گذشت سالها تجربه این AI را افزایش دهند که به تجسم اشیاء در دنیای واقعی بسیار کمک می کند.
شبکه هوش مصنوعی DeepMind به سادگی با بررسی یک دسته از تصاویر از صحنه های مشابه یکدیگر، از زوایای مختلف، می تواند طبق شهود خود، یک تصویر با کیفیت بهتر، به صورت سه بعدی و حتی می تواند تصاویر را از زاویه ای دیگر نشان دهد.
آقای اسلامی در یک مصاحبه تلفنی به ما گفت: “یکی از نتایج شگفت آور این برنامه این بوده که ما دیدیم که چگونه میتواند از چند سری عکس معمولی یک چشم انداز جدید، یکی شده، با تنظیمات روشنایی و سایه ها را به ما نشان دهد”.
وی همچنین گفت: “ما می دانیم که چگونه می توانیم تنظیمات رندرها و موتورهای گرافیکی را بنویسیم. اما بقیه کارها به عهده خود AI می باشد،می تواند تصاویر را پردازش کند و به صورت سه بعدی نمایش دهد و یا اینکه بعد از پردازش نسب به حدسیات خود صحنه مورد نظر شما را نشان دهد.
با این حال، آنچه در مورد نرم افزار DeepMind قابل توجه است این است که برنامه نویسان سعی نکردند این قوانین فیزیکی رندرینگ را با کد نویسی به نرم افزار بسپارند.
اسلامی گفت، در عوض، این نرم افزار با یک صفحه خالی آغاز می شود که می تواند با نگاهی به تصاویر، این قوانین رندرینگ را کشف کند.
این آخرین اظهارات و قابلیت های چند منظوره و باور نکردنی از شبکه های عصبی و هوش مصنوعی AI است.
همچنین ما می دانیم که آن ها ظرفیت قابل توجهی برای استدلال در مورد فضاهای سه بعدی نیز دارند.
شبکه پرس و جو و تولیدی DeepMind برای تولید یک صحنه سه بعدی چگونه کار می کند
در واقع شبکه تولیدی GQN دو شبکه عصبی عمیق مختلف است که با هم مرتبط هستند.
شبکه مجموعه ای از تصاویر را در یک قاب تصویر نشان می دهد (با یکدیگر و همراه با اطلاعات مربوط به مکان دوربین برای هر تصویر) و در نهایت این تصاویر متراکم را با یک الگوریتم ریاضی (اساسا به صورت وکتور و برداری) ترکیب می کند و یک نمونه از صحنه کلی را برای خود نمایش می دهد.
سپس این کار شبکه تولیدی است که این فرایند را به صورت بر عکس شروع کند: ابتدا صحنه ها را به صورت وکتور برای خود نشان می هد، موقعیت های مکانی را به عنوان ورودی می پذیرد و در نهایت تصویر نهایی را تولید می کند که نشان دهنده صحنه اصلی از همان زاویه است، فقط با این تفاوت که همه تصاویر را به صورت وکتور و در فضایی سه بعدی کنار یکدیگر چیده است.
بنابر این، اگر شما یک تصویر با موقعیت دوربین مربوط به یکی از تصاویر ورودی را بدهید، باید بتواند تصویر ورودی اصلی را بازتولید کند، اما در فضایی سه بعدی.
اما قابلیت پیشرفته دیگری که این برنامه ارائه می دهد استفاده از هوش مصنوعی است.
این شبکه تولیدی به کمک AI همچنین می تواند تصویرهای دیگری از موقعیت های مختلف دوربین را ارائه دهد که برای آن شبکه هیچکدام از آن تصاویر از قبل تعریف نشده است.
این قابلیت پیشرفته همچنان در حال بررسی می باشد و این قابلیت را دارد تا تصاویر را از زاویه های مختلف نشان دهد.
این تکنولوژی بر اساس حدس های AI امکان پذیر می شود، به گونه ای که با دادن تصویر های مختلف از زاویه های مختلف و پردازش آن ها، از زاویه مد نظر شما، بر اساس حدس های خود تصویر های وکتور مانندی می سازد و به شما ارائه می دهد و شما در نهایت می توانید تصویر مد نظر خود را از آن بگیرید.
این قسمت از برنامه نیاز به تمرین و کار کردن فراوان بر روی پردازش تصویر های مختلف دارد تا بتواند در آینده از زاویه های مختلف و خیلی بهتر از قبل تصاویر را رندر و پردازش کند.







![معرفی سرویس گوگل برای برنامه نویسان: کتابخانه توسعه [Dev Library]](https://netrun.ir/wp-content/uploads/2022/12/google-dev-library-intro-480x270.jpg)
